Exercise 3.11
%matplotlib inline
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(1)
# does not generate the same sequences as R
# it seems there's no easy, elegant way of getting Python and R to generate the same random sequences
# http://stackoverflow.com/questions/22213298/creating-same-random-number-sequence-in-python-numpy-and-r
x = np.random.normal(size=100)
y = 2*x+np.random.normal(size=100)
df = pd.DataFrame({'x': x, 'y': y})
fig, ax = plt.subplots()
sns.regplot(x='x', y='y', data=df, scatter_kws={"s": 50, "alpha": 1}, ax=ax)
ax.axhline(color='gray')
ax.axvline(color='gray')
<matplotlib.lines.Line2D at 0x118965588>
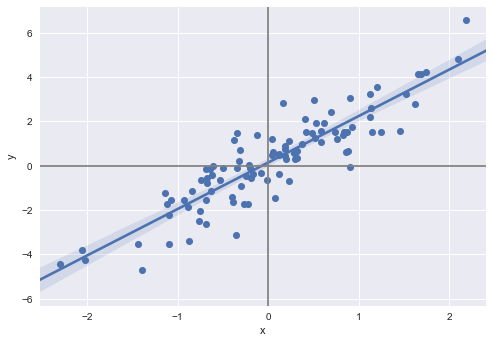
(a)
reg = smf.ols('y ~ x + 0', df).fit()
reg.summary()
| Dep. Variable: | y | R-squared: | 0.798 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.796 |
| Method: | Least Squares | F-statistic: | 391.7 |
| Date: | Fri, 08 Dec 2017 | Prob (F-statistic): | 3.46e-36 |
| Time: | 09:50:01 | Log-Likelihood: | -135.67 |
| No. Observations: | 100 | AIC: | 273.3 |
| Df Residuals: | 99 | BIC: | 275.9 |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| x | 2.1067 | 0.106 | 19.792 | 0.000 | 1.896 | 2.318 |
| Omnibus: | 0.880 | Durbin-Watson: | 2.106 |
|---|---|---|---|
| Prob(Omnibus): | 0.644 | Jarque-Bera (JB): | 0.554 |
| Skew: | -0.172 | Prob(JB): | 0.758 |
| Kurtosis: | 3.119 | Cond. No. | 1.00 |
From the table above, we see that the coefficient estimate \hat{\beta} = 2.1067 and the standard error of this coefficient estimate is 0.106. The t-statistic is equal to 19.792 and the p-value is close to 0 (less than 0.0005). We can therefore reject the null hypothesis and conclude that there is evidence for a relationship between x and y.
(b)
reg = smf.ols('x ~ y + 0', df).fit()
reg.summary()
| Dep. Variable: | x | R-squared: | 0.798 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.796 |
| Method: | Least Squares | F-statistic: | 391.7 |
| Date: | Fri, 08 Dec 2017 | Prob (F-statistic): | 3.46e-36 |
| Time: | 09:50:01 | Log-Likelihood: | -49.891 |
| No. Observations: | 100 | AIC: | 101.8 |
| Df Residuals: | 99 | BIC: | 104.4 |
| Df Model: | 1 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| y | 0.3789 | 0.019 | 19.792 | 0.000 | 0.341 | 0.417 |
| Omnibus: | 0.476 | Durbin-Watson: | 2.166 |
|---|---|---|---|
| Prob(Omnibus): | 0.788 | Jarque-Bera (JB): | 0.631 |
| Skew: | 0.115 | Prob(JB): | 0.729 |
| Kurtosis: | 2.685 | Cond. No. | 1.00 |
From the table above, we see that the coefficient estimate \hat{\beta} = 0.3789 and the standard error of this coefficient estimate is 0.019. The t-statistic is equal to 19.792 and the p-value is close to 0 (less than 0.0005). We can therefore reject the null hypothesis and conclude that there is evidence for a relationship between x and y.
(c)
As we can see from the two tables above, the t-statistics are the same, which means that the p-values are the same. Why the t-statistics are the same is the subject of question (e) below. Perhaps surprisingly, the coefficient estimates are not the inverse of each other. That is, \hat{\beta}_y \neq 1/ \hat{\beta}_x, where \hat{\beta}_y and \hat{\beta}_x are the coefficients of the models Y = \hat{\beta}_y X and X = \hat{\beta}_x Y, respectively. We know \hat{\beta}_x \simeq 2, but \hat{\beta}_y seems to be closer to 0.4 than 0.5. What is going on here?
The short answer: it has to do with the fitting method and with the non-symmetric loss function.
The visual insight is given in this answer. As the two figures in this link suggest, we are not minimizing the same loss function when we find the estimate coefficient.
This can also be seen algebraically. The coefficient estimates are the values that minimize the loss functions of ordinary least squares for these linear models without intercept, which leads to:
\hat{\beta}_y = \underset{\beta}{\operatorname{argmin}} \sum (y_i-\beta x_i)^2 = \frac{\sum y_i x_i}{\sum y_i^2} \left(= \frac{\operatorname{E}[X Y]}{\operatorname{E}[Y^2]} = \frac{\operatorname{E}[X Y] - \operatorname{E}[X]\operatorname{E}[Y]}{\operatorname{E}[(Y-\operatorname{E}[Y])^2]} = \frac{\operatorname{cov}(X, Y)}{\operatorname{var}(Y)}\right),
\hat{\beta}_x = \underset{\beta}{\operatorname{argmin}} \sum (x_i-\beta y_i)^2 = \frac{\sum y_i x_i}{\sum x_i^2} \left(= \frac{\operatorname{E}[X Y]}{\operatorname{E}[X^2]} = \frac{\operatorname{E}[X Y] - \operatorname{E}[X]\operatorname{E}[Y]}{\operatorname{E}[(X-\operatorname{E}[X])^2]} = \frac{\operatorname{cov}(X, Y)}{\operatorname{var}(X)}\right),
since \operatorname{E}[X]=\operatorname{E}[Y]=0.
Since the covariance is symmetric the coefficient estimates will depend on the respective variances. In other words, the coefficients estimates will depend on and differ by the respectives spreads of the data, \sum y_i^2 and \sum x_i^2.
We can see how the additional noise of Y breaks the symmetry. We know that the \operatorname{var}(X) = 1, so that \operatorname{var}(Y) = \operatorname{var}(2X + \epsilon ) = 4 \operatorname{var}(X) + \operatorname{var}(\epsilon) = 4 (1) + 1 = 5. Since \sum y_i x_i =\sum (2 x_i + \epsilon_i) x_i = 2 \sum x_i^2 + \sum x_i \epsilon_i \sim 2. So \hat{\beta}_x \sim 2/1 = 2 and \hat{\beta}_y \sim 2/5 = .4
If we use a loss function symmetrical in x and y (as the rectangles or total least squares regression, or PCA, figured below), then the coeffiecients will be the same.
(d)
This is a simple exercise of manipulating the formulas given.
We start with a simplification of a part of the formula for SE(\hat{\beta}):
$\sum_{i=1}^{n} (y_i - x_i \beta)^2 = \sum_{i=1}^{n} (y_i^2 - 2 x_i \beta + x_i^2 \beta^2) = \sum_{i=1}^{n} y_i^2 - 2 \beta \sum_{i=1}^{n} x_i + \beta^2 \sum_{i=1}^{n} x_i^2 $
which using the formula (3.38) from the text \hat{\beta}=\sum_{i=1}^{n} x_i y_i/\sum_{j=1}^{n} x_j^2 becomes:
$ \sum_{i=1}^{n} y_i^2 - 2 \frac{(\sum_{i=1}^{n} x_i y_i)^2}{\sum_{j=1}^{n} x_j^2 } + \frac{(\sum_{i=1}^{n} x_i y_i)^2}{\sum_{j=1}^{n} x_j^2 } = \sum_{i=1}^{n} y_i^2 - \frac{(\sum_{i=1}^{n} x_i y_i)^2}{\sum_{i=1}^{n} x_i^2 }.$
With this, we restart from the formula for the t-statistic and simplify:
$\frac{\hat{\beta}}{SE(\hat{\beta})}= \frac{(\sum_{i=1}^{n} x_i y_i) \sqrt{n-1} \sqrt{\sum_{i=1}^{n} x_i^2} }{ ( \sum_{i=1}^{n} x_i^2 ) \sqrt{\sum_{i=1}^{n} (y_i - x_i \beta)^2}} = \frac{(\sum_{i=1}^{n} x_i y_i) \sqrt{n-1} }{ \sqrt{ (\sum_{i=1}^{n} x_i^2 ) \sum_{i=1}^{n} (y_i - x_i \beta)^2}} $
where we now substitute our previous simplification in the denominator:
$ \frac{(\sum_{i=1}^{n} x_i y_i) \sqrt{n-1} }{ \sqrt{ (\sum_{i=1}^{n} x_i^2 ) \left( \sum_{i=1}^{n} y_i^2 - \frac{(\sum_{i=1}^{n} x_i y_i)^2}{\sum_{i=1}^{n} x_i^2 } \right)}} = \frac{ (\sqrt{n-1} ) \sum_{i=1}^{n} x_i y_i }{ \sqrt{ (\sum_{i=1}^{n} x_i^2 )( \sum_{i=1}^{n} y_i^2 ) - (\sum_{i=1}^{n} x_i y_i)^2 } }, $
as we wanted.
(e)
Since the expression for the t-statistic is symmetric in x_i and y_i, it will have the same value whether we regress Y on X or X on Y.
(f)
regyx = smf.ols('y ~ x', df).fit()
regxy = smf.ols('x ~ y', df).fit()
print(regyx.tvalues)
print(regxy.tvalues)
Intercept 1.564347
x 19.782585
dtype: float64
Intercept -1.089559
y 19.782585
dtype: float64